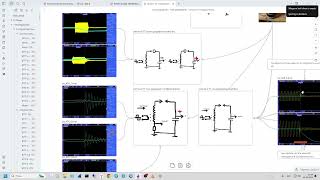
Apache Spark is a dynamic execution engine that can take relatively simple Scala code and create complex and optimized execution plans. In this talk, we will describe how user code translates into Spark drivers, executors, stages, tasks, transformations, and shuffles. We will also discuss various sources of information on how Spark applications use hardware resources, and show how application developers can use this information to write more efficient code. We will show how Pepperdata’s products can clearly identify such usages and tie them to specific lines of code. We will show how Spark application owners can quickly identify the root causes of such common problems as job slowdowns, inadequate memory configuration, and Java garbage collection issues.
About: Databricks provides a unified data analytics platform, powered by Apache Spark™, that accelerates innovation by unifying data science, engineering and business.
Read more here: [ Ссылка ]
Connect with us:
Website: [ Ссылка ]
Facebook: [ Ссылка ]
Twitter: [ Ссылка ]
LinkedIn: [ Ссылка ]
Instagram: [ Ссылка ] Databricks is proud to announce that Gartner has named us a Leader in both the 2021 Magic Quadrant for Cloud Database Management Systems and the 2021 Magic Quadrant for Data Science and Machine Learning Platforms. Download the reports here. [ Ссылка ]



![Галилео | Роллтон 🥡 [Rollton]](https://s2.save4k.su/pic/HwY61r9-A-o/mqdefault.jpg)