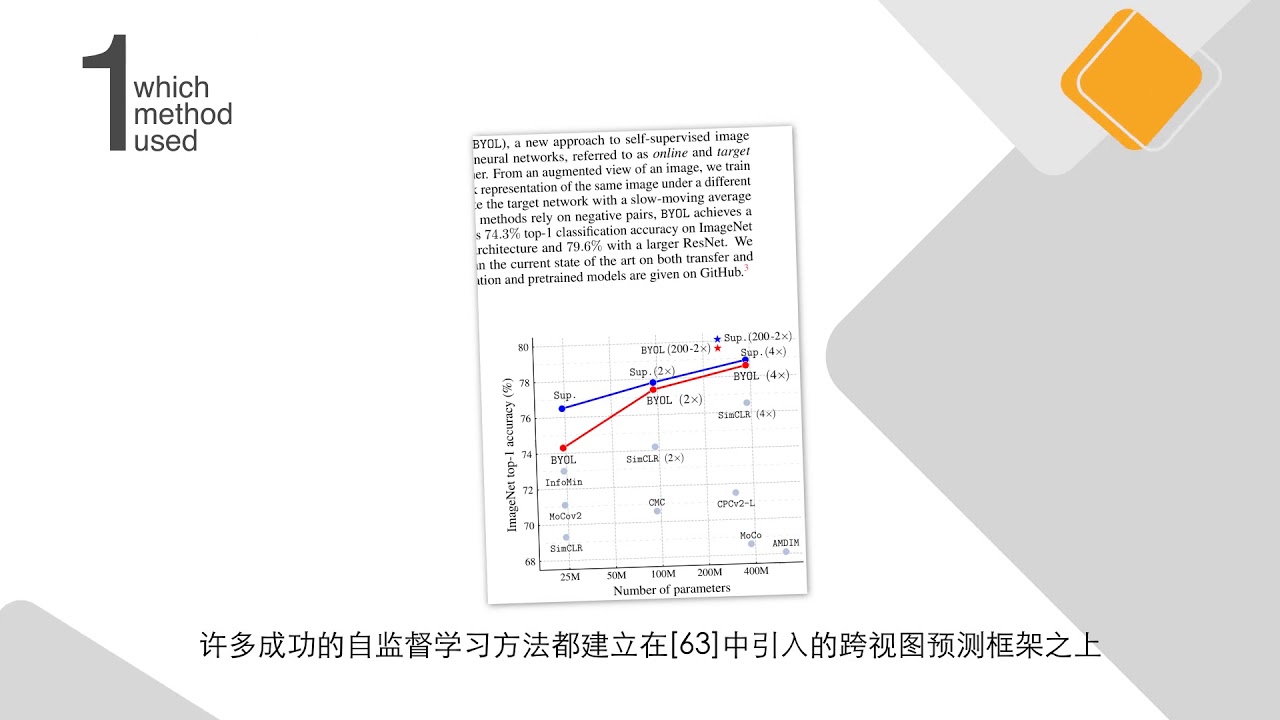
The authors start by motivating the method before explaining its details in Section 3.1. Many successful self-supervised learning approaches build upon the cross-view prediction framework introduced in [63].
To ascertain that BYOL learns good representations on other datasets, the authors applied the representation learning protocol on the scene recognition dataset Places365-Standard [73] before performing linear evaluation
This dataset contains 1.80 million training images and 36500 validation images with labels, making it roughly similar to ImageNet in scale.
All three unsupervised representation learning methods achieve a relatively high performance on the Places365 task; for comparison, reference [73] reports a top-1 accuracy of 55.2% for a ResNet-50v2 trained from scratch using labels on this dataset.
This shows that making the prediction targets stable and stale is the main cause of the improvement rather than the change in the objective due to the stop gradient
[ Ссылка ]
#AI #AMiner #NeurIPS 2020 #MachineLearning #Artificialintelligence