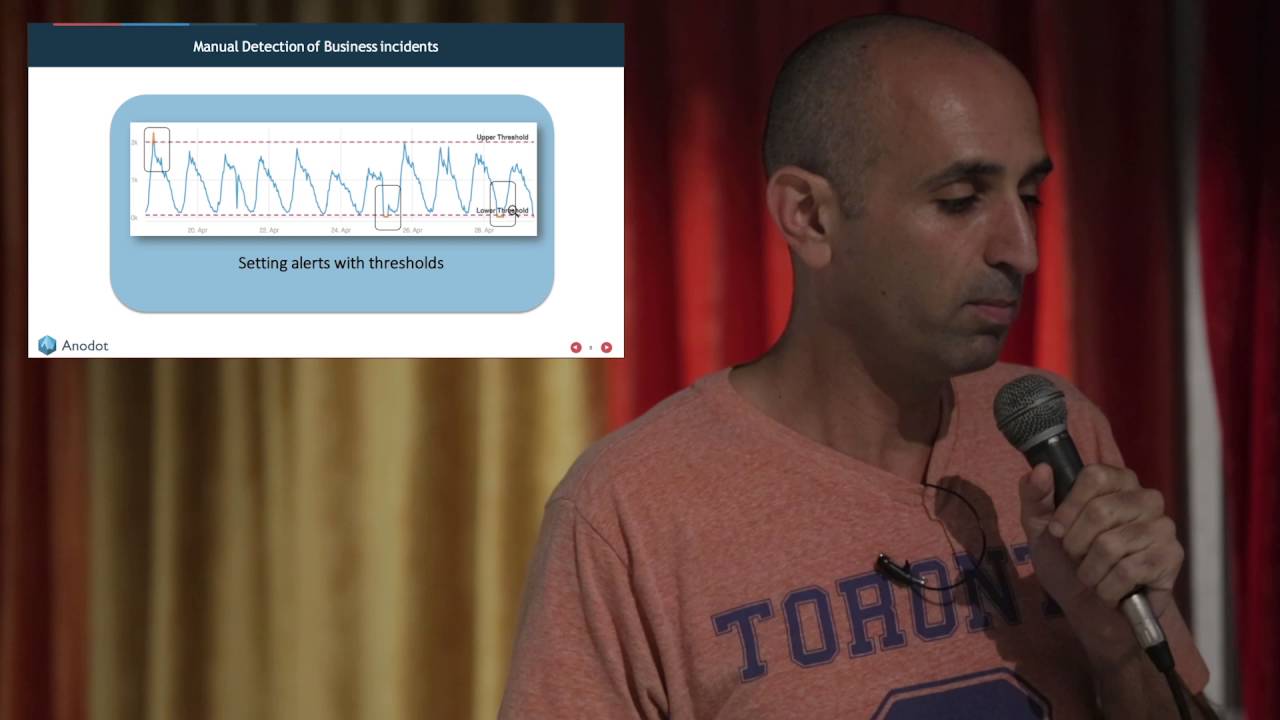
When a business grows, it grows in lots of ways - more customers/revenue, employees, support needs, software, hardware, etc. The growth involves all parts of a company, and with it the need to manage and track all parts in a scalable way. Collecting metrics (measurements over time of performance indicators) is the first step to keep track of the business performance - from revenue, customer acquisition and churn, marketing KPIs, application performance KPIs (errors, latency, etc) , IT performance and more. A small business can keep track of these with various visualization tools (e.g., dashboards). As the business scales, these tools do not — the amount of things to track becomes too large for manual inspection.
This is where automated anomaly detection becomes fundamental. Anomaly detection, a branch of machine learning and statistics, automatically discovers and highlights strange patterns in any metric, enabling the business to react to them. Anomalies can be good - anomalous increase in revenue of a certain product, increase in service usage and more, or bad — decrease in # of users, revenue, or increase in errors of an application. Each anomaly should be tied to the appropriate action - call a customer, restart a service or add a host
The talk focuses on two main themes:
1. Explanation on anomaly detection
-What is it?
-Fundamental techniques in machine learning for doing anomaly detection.
-Requirements from an anomaly detection system in various use cases
-Issues and pitfalls to watch out for when implementing anomaly detection
2. How to use anomaly detection?
-Common use cases and examples
-Reacting to anomalies - defining the process.
-Case study- tracking machine learning algorithms in production with anomaly detection.
























































![Deep House Music - Best of Ethnic Chill & Deep House Mix [1 Hours]](https://s2.save4k.su/pic/h2pMSKacoe4/mqdefault.jpg)




![[4K] NURSE TAKES CARE OF YOU CALI | AI LOOKBOOK](https://s2.save4k.su/pic/j6QEzjBhjCU/mqdefault.jpg)





![Relaxing Morning Stretching in Bed with Shakti [4K]](https://s2.save4k.su/pic/qw3Bt2iBfjU/mqdefault.jpg)



