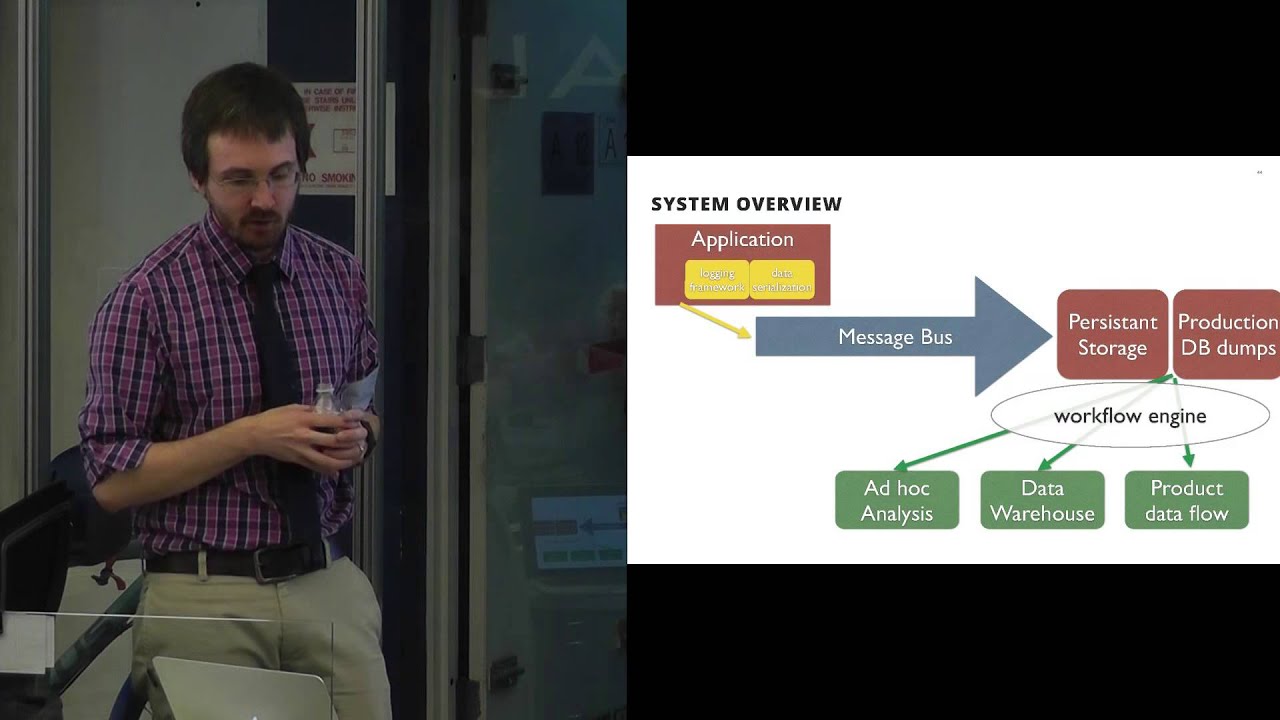
Big data processing with Apache Hadoop, Spark, Storm and friends is all the rage right now. But getting started with one of these systems requires an enormous amount of infrastructure, and there are an overwhelming number of decisions to be made. Oftentimes you don't even know what kinds of questions you can or should be answering with your data.
As a first step, Joe describes the types of problems that people typically solve with a data pipeline—things like A/B testing and data warehousing. Then, drawing from his personal experience of building data tools at Foursquare and a from-scratch data pipeline at a new startup, he'll highlight the key questions to ask and best practices you should implement to encourage success.
ABOUT DATA COUNCIL:
Data Council ([ Ссылка ]) is a community and conference series that provides data professionals with the learning and networking opportunities they need to grow their careers. Make sure to subscribe to our channel for more videos, including DC_THURS, our series of live online interviews with leading data professionals from top open source projects and startups.
FOLLOW DATA COUNCIL:
Twitter: [ Ссылка ]
LinkedIn: [ Ссылка ]
Facebook: [ Ссылка ]
Eventbrite: [ Ссылка ]