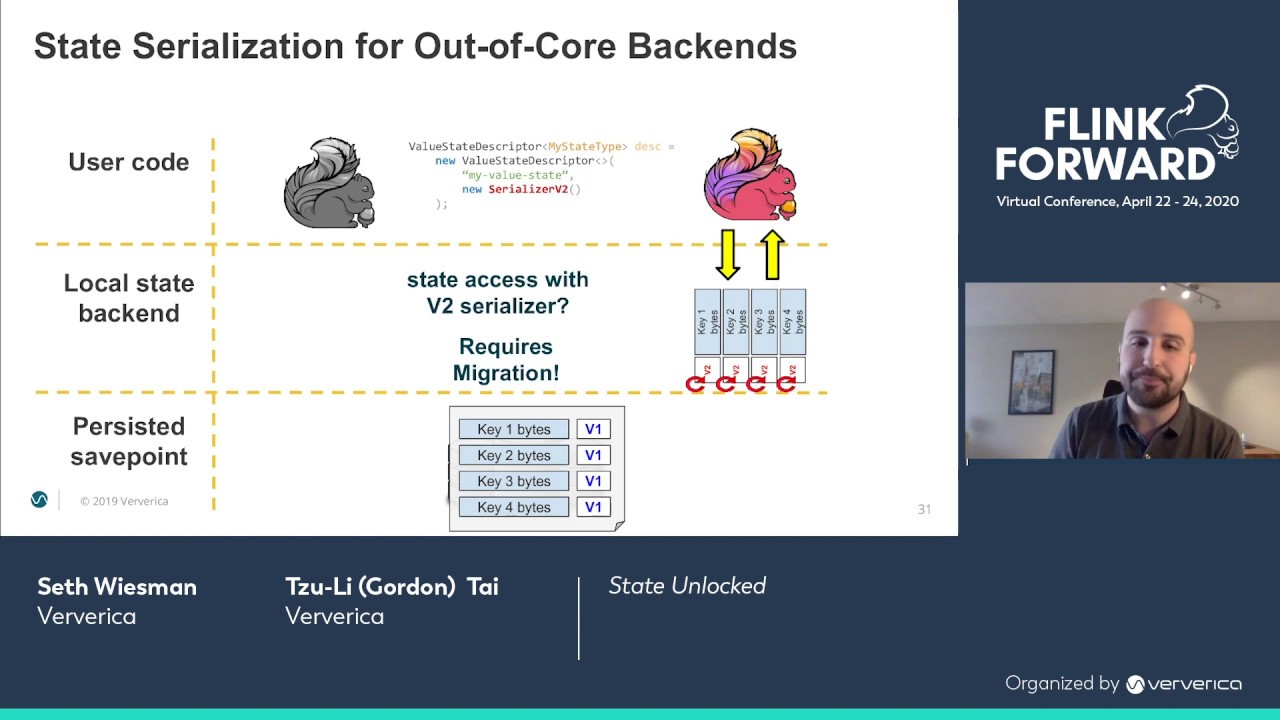
As stateful streaming processing becomes more and more mature for complex event-driven applications and real-time analytics, users have put Apache Flink into the center of their business logic and entrusted it to manage their most valuable assets, their application data, as internal state of Flink streaming pipelines. At the same time, the Flink community has continued efforts to make sure that users feel safe and future-proof in doing that. They should have sufficient means to access and modify their state, as well as making it much easier to bootstrap state with existing data from external systems. These efforts span multiple Flink major releases and consists of the following: 1) evolvable state schema, 2) flexibility in swapping state backends, and 3) an offline tool to read, process, and create new snapshots that streaming applications can bootstrap its state with. In this talk, we will go over these topics and demonstrate how users can interact with state with the availability of these new features.