Speaker: Eric Wong, University of California, San Diego
Title: The Shallow Brain
Emcee: Alexander Arguello
Backend host: Arash Ash
Details: [ Ссылка ]
Presented during Neuromatch Conference 3.0, Oct 26-30, 2020.
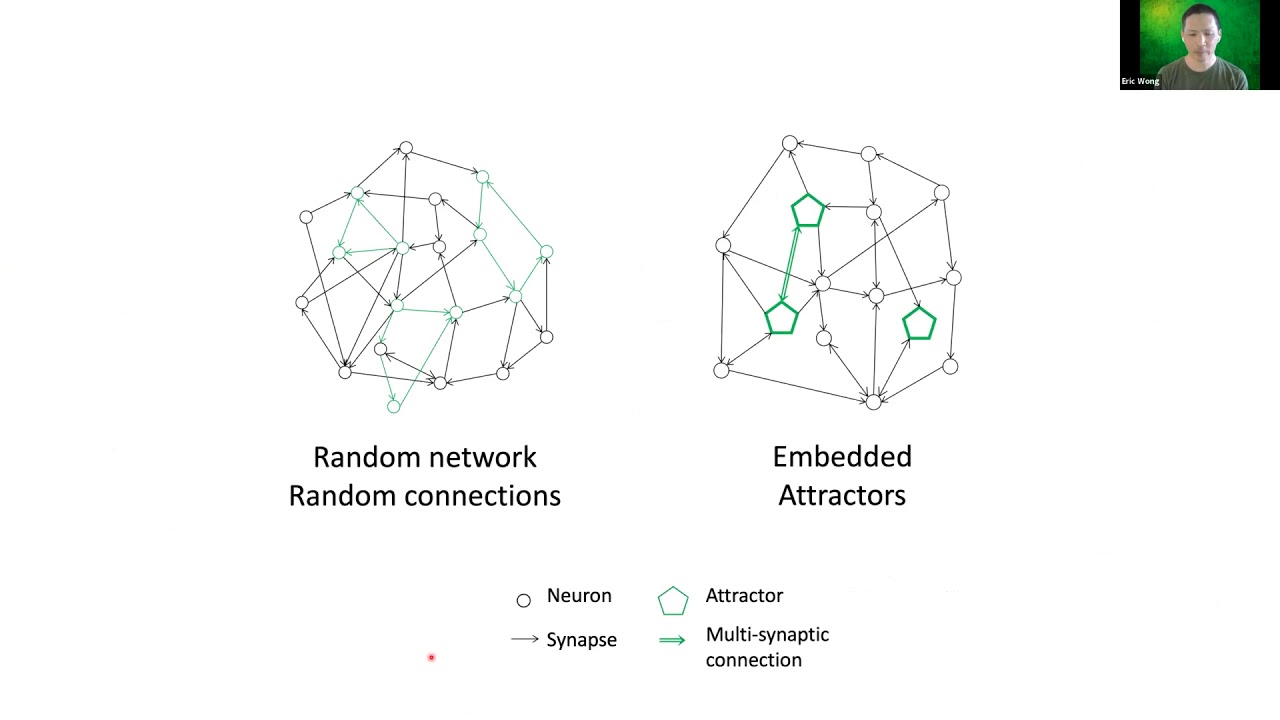
Summary: We present here a model for the core computational architecture that supports cognitive processes in the brain. We base our model on three premises: 1) The brain represents abstractions as groups of active neurons, here referred to as attractors. 2) Most learning is implemented by creating associations between abstractions, exemplified by classical conditioning or learning the many incremental associations we are taught in our first few decades of life that impress into our brains the distilled accumulated intelligence of our species. 3) Any combination of attractors can serve as either input or output for a given association. Together these suggest that the architecture of the brain is primarily an unstructured network, where new attractors can be created as new abstractions are learned, and associated with other attractors. The well-established STDP mechanism has been shown to support both the construction and association of attractors from an initially random network.
Such a network may account for aspects of cognition that are composed of explicit associations between identifiable abstractions, but likely does not support the unconscious, automatic, or intuitive processing that implement implicit thought. We hypothesize that the associative network of attractors is embedded in (and derives from) a background of randomly connected neurons, and that the action of the associative network can train this background network to implement implicit thought by exciting the desired output attractors and connecting them by STDP to active neurons in the background network, much as in reservoir learning. If this process is repeated using an incremental learning curriculum, the background network can develop elements that are functionally hierarchical, despite a lack of initial structure.
We note that the architecture described here is amenable to single-shot learning, and because it does not propagate signals for synaptic changes through the network, likely insensitive to catastrophic forgetting.








![Звуковые иллюзии, которые работают на всех (почти) [Veritasium]](https://i.ytimg.com/vi/8pCuUfbdheE/mqdefault.jpg)