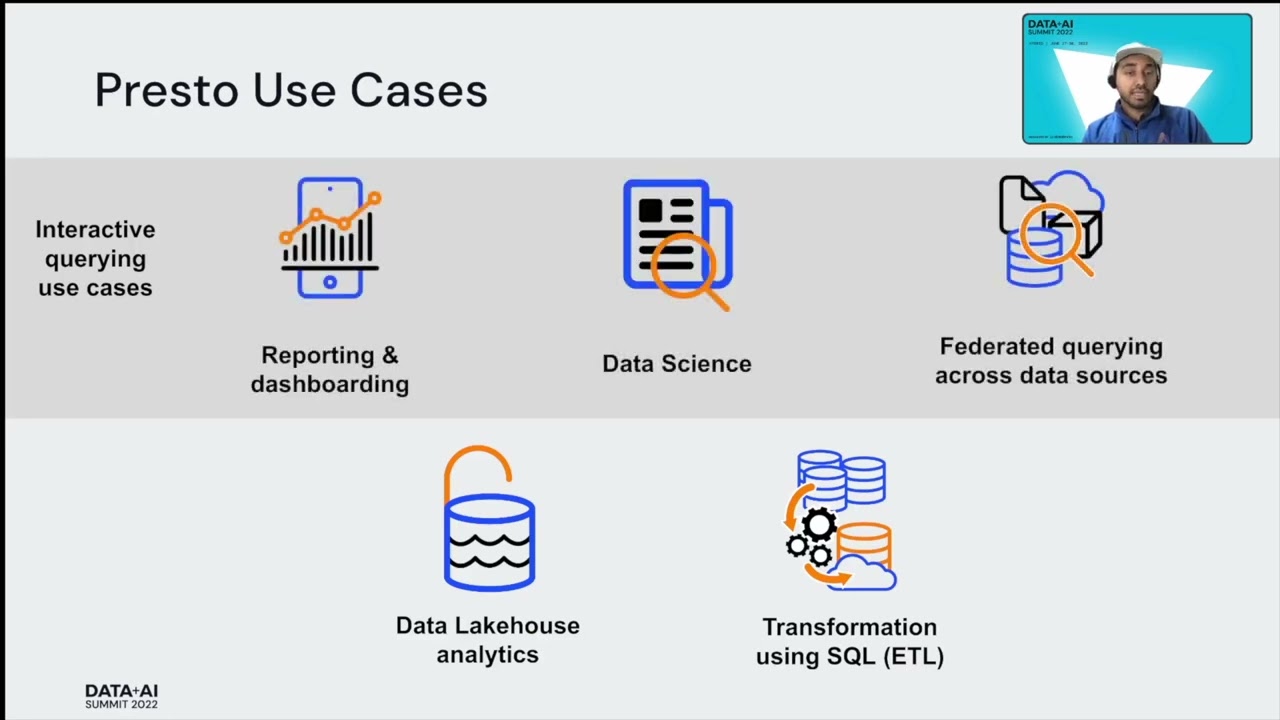
Presto is a widely adopted distributed SQL engine for data lake analytics. With Presto, you can perform ad hoc querying of data in place, which helps solve challenges around time to discover and the amount of time it takes to do ad hoc analysis. Additionally, new features like the disaggregated coordinator, Presto-on-Spark, scan optimizations, a reusable native engine, and a Pinot connector enable added benefits around performance, scale, and ecosystem.
In this session, Philip and Rohan will introduce the Presto technology and share why it’s becoming so popular – in fact, companies like Facebook, Uber, Twitter, Alibaba, and much more use Presto for interactive ad hoc queries, reporting & dashboarding data lake analytics, and much more. We’ll also show a quick demo on getting Presto running in AWS.
Connect with us:
Website: [ Ссылка ]
Facebook: [ Ссылка ]
Twitter: [ Ссылка ]
LinkedIn: [ Ссылка ]...
Instagram: [ Ссылка ]